We continue our journey with Python. At the end of this week, you will be able to:
Practice using statsmodels library for statistical analysis
Exercise using Scikit-learn library for machine learning
Create plots using Matplotlib and seaborn
Statistical Models in Python
statsmodels is a Python package that provides functions for fitting statistical models, conducting statistical tests, and statistical data exploration.
Let’s read a data set from the list provided in this link. We use the mtcars data set in R package datasets.
# allow to access easily to most of the functionsimport statsmodels.api as stat # allow to use formula style to fit the modelsimport statsmodels.formula.api as statf import pandas as pdimport numpy as np# matplotlib for plotsimport matplotlib.pyplot as plt# load data "mtcars" from the R package 'datasets' mtcars_python = stat.datasets.get_rdataset("mtcars", "datasets").data # print dataprint(mtcars_python.info())# fit linear regression
fit_olsregression = statf.ols("mpg ~ wt + cyl",data=mtcars_python).fit()# print linear regression resultsprint(fit_olsregression.summary())# predict using linear regression
The scikit-learn provides function that support machine learning techniques and practices including model fitting, predicting, cross-validation, etc. It also provides various supervised and unsupervised methods. The website of the package is https://scikit-learn.org
Linear models
Fitting regression models is relevant when the target value or response variable is assumed to be a linear combinations of some predictors. The following code will allow you to fit various linear models using sklearn module.
# import librariesfrom sklearn import linear_modelfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_absolute_percentage_error# Load datadf = stat.datasets.get_rdataset("mtcars", "datasets").data # split datatraining_data, testing_data = train_test_split(df, test_size=0.2, random_state=25)# Create X and Y from trainingY = training_data["mpg"] # response variable / outcomeX = training_data.drop(columns=["mpg"]) #predictors / featuresreg = linear_model.LinearRegression().fit(X,Y)# Create X and Y from testingY_test = testing_data["mpg"] # response variable / outcomeX_test = testing_data.drop(columns=["mpg"]) #predictors / featuresmpg_y_pred = reg.predict(X_test) # predictionsprint(reg.coef_)# Compute the MAPE
The matplotlib.pyplot module is a collection of command style functions that make matplotlib work like MATLAB.
A few plots!
# import librariesimport matplotlib.pyplot as pltimport numpy as npimport matplotlib#matplotlib.use('Agg') # To plot with Markdownx = np.linspace(0, 10, 100)plt.figure();plt.plot(x, np.sin(x))plt.plot(x, np.cos(x))plt.show()
plt.close()
Read data from sklearn and vizualize
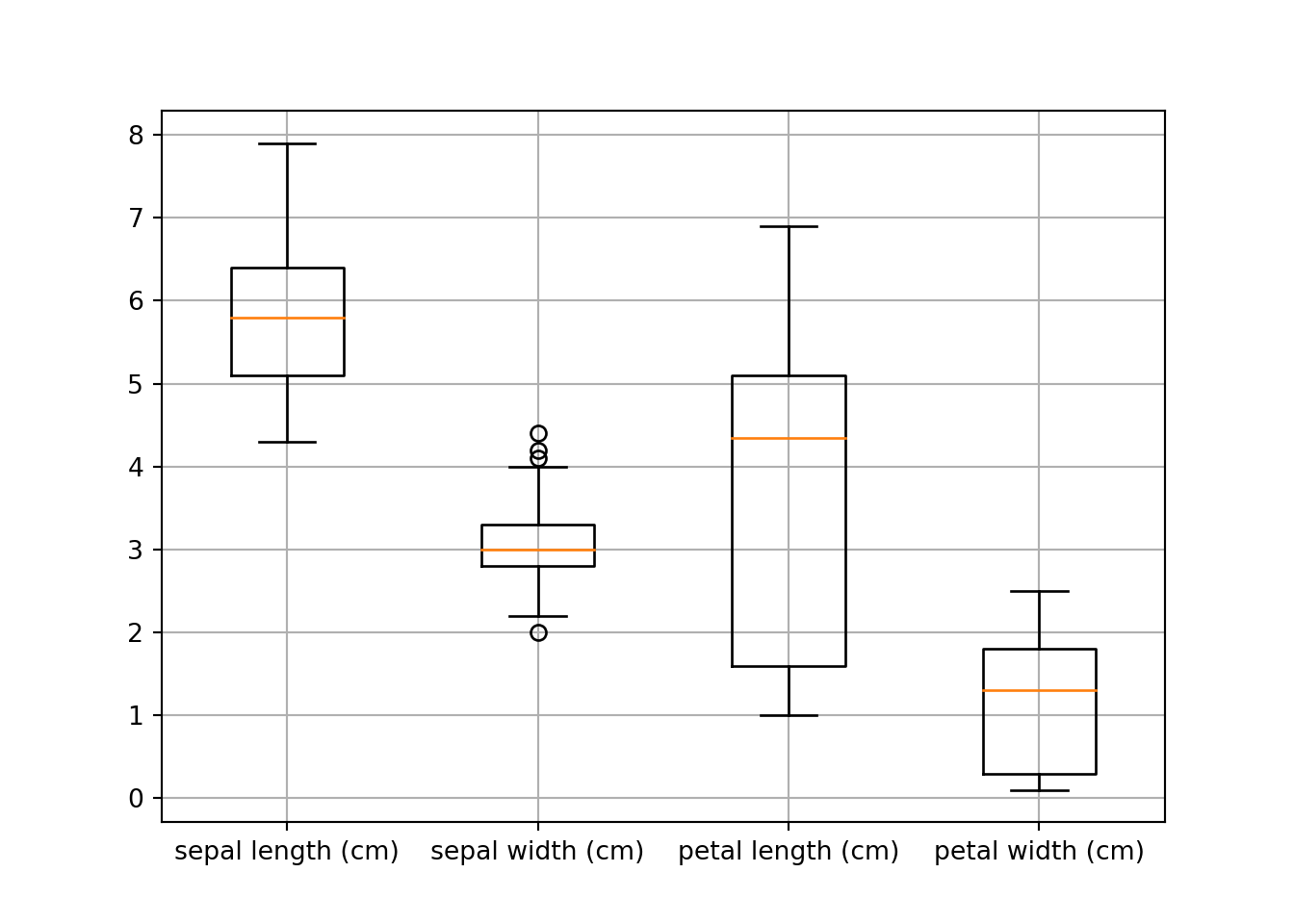
import matplotlib.pyplot as pltimport pandas as pdfrom sklearn.datasets import load_iris import matplotlib#matplotlib.use('Agg') # To plot with Markdown# load iris datairis = load_iris()# make iris data a Pandas data framedf_iris = pd.DataFrame(iris.data)# features names as columns namedf_iris.columns = iris.feature_names# Boxplotplt.figure();plt.boxplot(df_iris)
{'whiskers': [<matplotlib.lines.Line2D object at 0x13567a880>, <matplotlib.lines.Line2D object at 0x135650af0>, <matplotlib.lines.Line2D object at 0x135bb9910>, <matplotlib.lines.Line2D object at 0x135bb9bb0>, <matplotlib.lines.Line2D object at 0x135bcabb0>, <matplotlib.lines.Line2D object at 0x135bcae50>, <matplotlib.lines.Line2D object at 0x135bd7e50>, <matplotlib.lines.Line2D object at 0x135be5130>], 'caps': [<matplotlib.lines.Line2D object at 0x13567ab80>, <matplotlib.lines.Line2D object at 0x13567ae20>, <matplotlib.lines.Line2D object at 0x135bb9e50>, <matplotlib.lines.Line2D object at 0x135bca130>, <matplotlib.lines.Line2D object at 0x135bd7130>, <matplotlib.lines.Line2D object at 0x135bd73d0>, <matplotlib.lines.Line2D object at 0x135be53d0>, <matplotlib.lines.Line2D object at 0x135be5670>], 'boxes': [<matplotlib.lines.Line2D object at 0x13567a5e0>, <matplotlib.lines.Line2D object at 0x135bb9670>, <matplotlib.lines.Line2D object at 0x135bca910>, <matplotlib.lines.Line2D object at 0x135bd7bb0>], 'medians': [<matplotlib.lines.Line2D object at 0x135bb9100>, <matplotlib.lines.Line2D object at 0x135bca3d0>, <matplotlib.lines.Line2D object at 0x135bd7670>, <matplotlib.lines.Line2D object at 0x135be5910>], 'fliers': [<matplotlib.lines.Line2D object at 0x135bb93a0>, <matplotlib.lines.Line2D object at 0x135bca670>, <matplotlib.lines.Line2D object at 0x135bd7910>, <matplotlib.lines.Line2D object at 0x135be5bb0>], 'means': []}
plt.xticks([1, 2, 3, 4], iris.feature_names)
([<matplotlib.axis.XTick object at 0x135648670>, <matplotlib.axis.XTick object at 0x135648640>, <matplotlib.axis.XTick object at 0x135be5fa0>, <matplotlib.axis.XTick object at 0x135bf4520>], [Text(1, 0, 'sepal length (cm)'), Text(2, 0, 'sepal width (cm)'), Text(3, 0, 'petal length (cm)'), Text(4, 0, 'petal width (cm)')])
Data was obtained from the Federation Aviation Administration (FAA) in June 2023 on pilot certification records and contained the following:
Pilot ID,
CertLevel: the certification level (Airline, Commercial, Student, Sport, Private, and Recreational),
STATE: the USA state,
MedClass: the medical class,
MedExpMonth: the medical expire month, and
MedExpYear: the medical expire year.
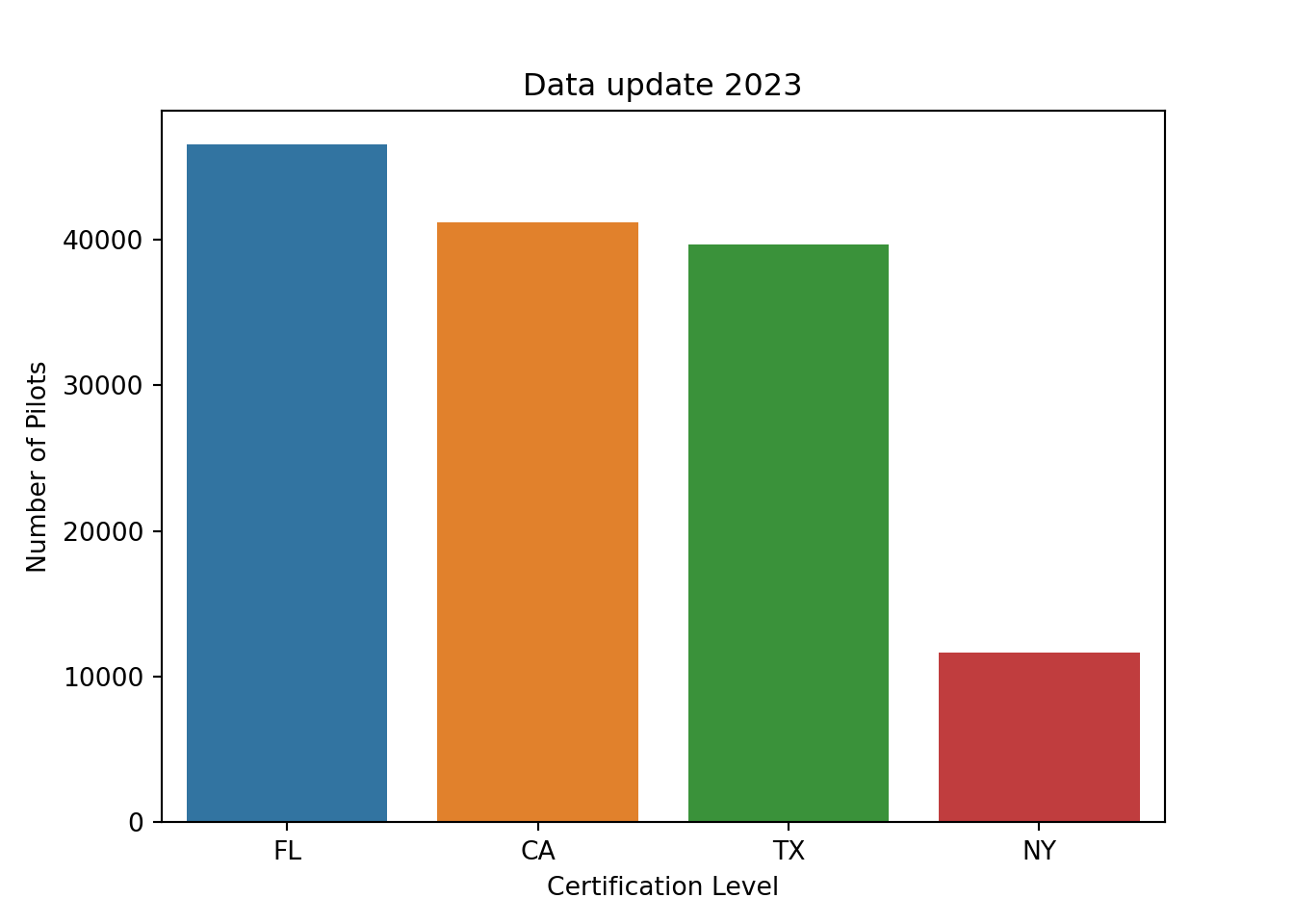
Number of Pilots per State
import matplotlib.pyplot as pltimport pandas as pdimport matplotlibfrom collections import Counterimport seaborn as snsdf = pd.read_csv("../datasets/pilotsCertFAA2023.csv")print(df.info())# Select FL, CA, NY, and TX state
st = ['FL', 'CA', 'NY', 'TX']df_reduced = df[df['STATE'].isin(st)]# Counts how many in each statecounts = Counter(df_reduced.STATE)# Convert to data framedf_reduced = pd.DataFrame.from_dict(counts, orient='index').reset_index()# Rename columnsdf_reduced = df_reduced.rename(columns={'index':'state', 0:'count'})# bar plot with seabornaxx = sns.barplot(data=df_reduced, x="state", y="count")# add x and y labelsaxx.set(xlabel='Certification Level', ylabel='Number of Pilots', title="Data update 2023")plt.show()
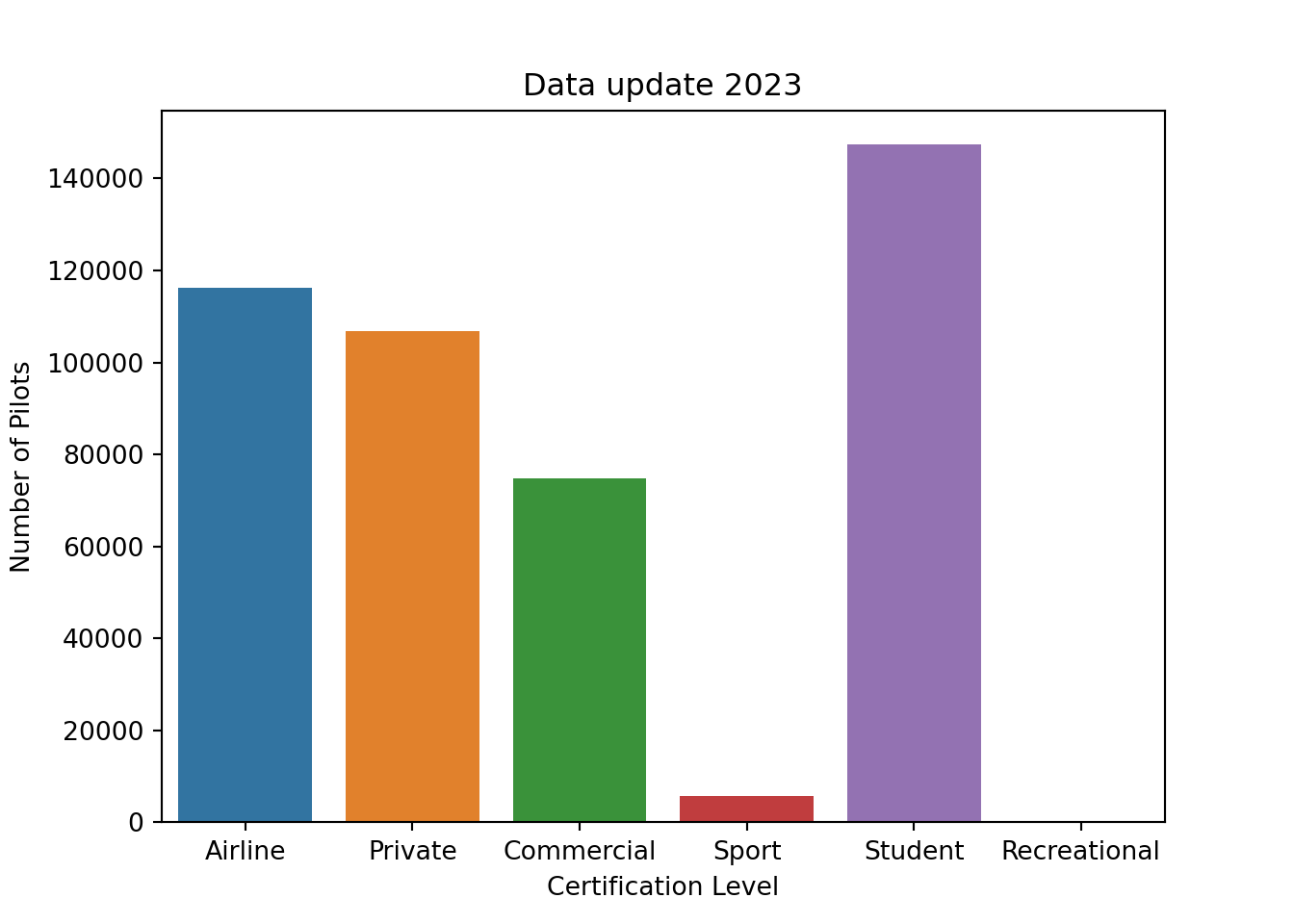
Number of Pilots per Certification Level
# Counts how many in each certification levelcountsCert = Counter(df.CertLevel)# Convert to data framedf_reduced_cert = pd.DataFrame.from_dict(countsCert, orient='index').reset_index()# Rename columnsdf_reduced_cert = df_reduced_cert.rename(columns={'index':'certlevel', 0:'count'})# bar plot with seabornax = sns.barplot(data=df_reduced_cert, x="certlevel", y="count")# add x and y labelsax.set(xlabel='Certification Level', ylabel='Number of Pilots', title="Data update 2023")plt.show()
🛎 🎙️ Recordings on Canvas will cover more details and examples! Have fun learning and coding 😃! Let me know how I can help!